-
[openCV] tesseract를 이용해서 이미지의 텍스트 추출프로젝트 기록/졸업 프로젝트 2022. 5. 23. 22:36
1. tesseract 다운 받기
GitHub - UB-Mannheim/tesseract: Tesseract Open Source OCR Engine (main repository)
Tesseract Open Source OCR Engine (main repository) - GitHub - UB-Mannheim/tesseract: Tesseract Open Source OCR Engine (main repository)
github.com
2. 환경변수 설정

3. cmd 창에 pytesseract 설치
pip install pytesseract4. cmd 창 열고 다음 명령어 실행
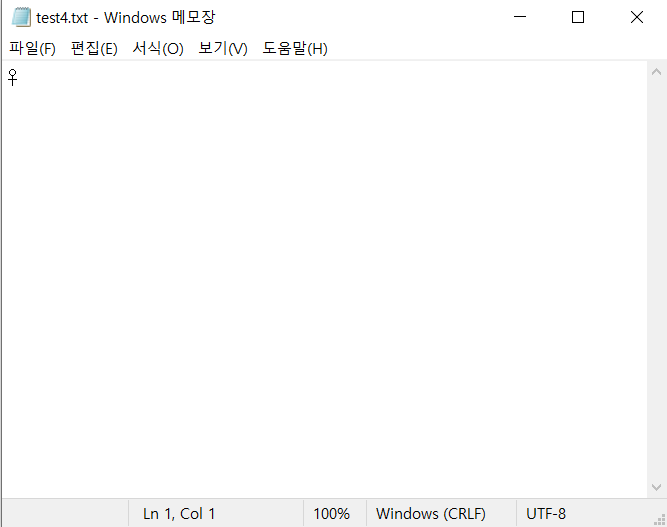
분명 방법은 맞는데 .... 왜 숫자 인식이 안될까 ?
tesseract test2.png test4 -l kor


5. 이미지 전처리
난 아나콘다에서 진행함 -> 주피터 노트북
opencv를 이용하기 위해 가상환경에 모듈을 미리 설치해줬음
pip install opencv-pythonpip install opencv-contrib-python
https://turtle-dennis.tistory.com/30?category=843819
[Tesseract & OpenCV]를 이용한 OCR-2-1 전처리(pre-processing)
Tesseract & OpenCV 지난번에 이어 오늘은 테서랙트와 OpenCV를 이용한 OCR에서 OCR 정확도를 높이기 위해 이미지 전처리에 대해 알아보겠습니다. OpenCV는 Open source computer vision library의 약자로 이미지/..
turtle-dennis.tistory.com
이분꺼 참고하여 진행함..
import pytesseract import cv2 import matplotlib.pyplot as plt import numpy as np path ="C:/Users/lyh_1/Desktop/project_1/opencv_test/" image_can = cv2.imread(path + 'test.jpg', cv2.IMREAD_COLOR) #color -> grayscale def gray_scale(image): result = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) return result #grayscale -> binary def image_threshold(image): result = cv2.threshold(image,0,255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) [1] return result #delation def dilation(image): kernel = np.ones((5,5), np.uint8) result = cv2.dilate(image, kernel, iterations=1) return result #erosion -> dilation def opening(image): kernel = np.ones((5,5),np.uint8) result = cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel) return result image_can_gray = gray_scale(image_can) image_can_binary = image_threshold(image_can_gray) image_can_open = opening(image_can_binary) image_car_dilate = dilation(image_can_binary) # plt.figure(figsize=[20,7]) # plt.subplot(1,2,1) # plt.imshow(image_car_dilate) # plt.xlabel("Original binary", fontsize=15) # print("image_can shape: ", image_can_binary.shape) plt.subplot(1,2,2) plt.imshow(image_can_open) plt.xlabel("opening", fontsize=15) print("opening image shape: ", image_can_open.shape) plt.savefig('opening2.png')
6. 다시 tesseract를 실행해보자..!

, , , , ,

일단 오늘은 여기서 끝
'프로젝트 기록 > 졸업 프로젝트' 카테고리의 다른 글
221018 백업 (0) 2022.10.18 모델 합치기 (0) 2022.04.26 colab에서 이미지 크롤링하기 (2) 2022.04.21 크롤링해서 이미지 모으기 (2) 2022.04.12 사진 더 추가하고 학습시키기 (2) 2022.04.11